How I Built a Power Debugger Out of the Standard Library and Things I Found on the Internet
The video for my talk last week at PyCon 2016 is available on YouTube now. I’ve also included the talk that I wrote (not necessarily exactly what I delivered, but close) below.
Today I am going to talk a bit about how I glued together modules from the standard library and a few other packages to make a python power debugger.
The project I will be talking about runs along side your program, and watches not just how the code is executed but also all of the values of all variables, recording them to produce a complete trace of the project’s execution history for you to examine at your leisure.
But before we go too far into detail I want to make sure that I’ve set your expectations clearly.
Most project-based presentations are set up to cover the project and its features, often with demos. Those are great talks, and they’re a big part of why we all come to conferences. If I was giving a talk like that the title would have a different emphasis.
But that’s not what I want to do today. Instead I want to talk about how I built it.
It’s easy to forget, when you watch a bunch of conference talks announcing new projects, that these things don’t spring fully formed into the world. Creating them takes continual effort, often over a significant period of time.
During the years that I’ve been leading the Python meetup in Atlanta, I’ve found that some of the best received talks cover more than how to use a tool. They talk about how the speaker learned about a tool and how their project that uses it grew. How they made decisions, weighed their options, and experimented as they created.
It’s important to talk about the evolutionary process projects go through and show how to start with something simple and build something more complex. How to add features carefully, adjusting existing code as you go, while maintaining backwards compatibility. And how to recognize when you’re going down the wrong path, and make that tough decision that it’s time to abandon something to start again.
So what I want to focus on, more than the implementation details of the program, are the thought processes I followed as I was working and the story of how I created the project I call smiley.
I will show code and talk about the tools as I tell the story, but there’s too much code to really walk through all of it, so if you’re the sort of person who reads the last page of a book before starting it, you may want to go ahead and jump into the github repo or documentation and look around.
Choosing a Name
First things first, what’s up with the name? When I started thinking about the design for this tool, I thought of it as “spying” on what the program was doing.
So of course, I started thinking of spy names.
James Bond was way too obvious. I wanted something subtle, so I settled on George Smiley, the John le Carré character.

He’s more intellectual, less flashy, and is focused on the mental side spying rather than shooting things up. That’s more my style.
Plus, you can’t go wrong with Alec Guiness.
Planning
With the naming question resolved, I could get down to business and start planning the features I wanted smiley to have.
I wanted to record the same data you might expect to see in a live debugger like pdb, but without tediously stepping through calls. I also wanted the best of “print” based debugging, without having to decide in advance which values to print out.
I wanted to record all function calls, and the data involved. I wanted to support remote debugging, since we’re all running all of our software in the cloud these days anyway. And I wanted to have a way to browse old runs and analyze them locally.
I was also motivated to build something just a little audacious, to see how far I could take the idea, and learn some new tools along the way.
I had worked with Python’s trace API before, so I knew enough to believe I could make that work for me. And I’ve done network programming before, so I knew if it came down to it I could build the remote execution part.
Stumbling Through ZeroMQ
But I also wanted to try the networking library ZeroMQ, a new tool for me, as part of the project. That involved reading a lot of documentation and poking around with some different experimental scripts that I didn’t save, just to see how to make the parts fit together. I mostly had no idea what I was doing, so I just keep trying to get the 2 programs to talk until they did. It took me a week or so of spare-time sessions to make them talk reliably, in part because I made a bad choice early on.
Initially I used PUB/SUB sockets because I was communicating one way and thought maybe I wanted to support multiple listeners, but I was having trouble with losing messages.
It turns out that PUB/SUB doesn’t ensure message delivery, so the first couple of messages were often thrown away before communication was established. So after some frustrating debugging sessions, I eventually realized that choice was a mistake and switched to a PUSH/PULL socket pair.
As part of my experimentation, I created a pair of classes that I could use to send arbitrary messages one way between two processes, a publisher and a listener. This abstracted my application’s needs to send a message, from the implementation detail of doing that with a particular ZeroMQ socket type (or indeed ZMQ at all).
Tracing Python Programs
After I had the publisher and listener classes I created a tracer class that uses the communication classes to publish data about what is happening inside a program as it runs.
The tracer works by installing its trace_calls() method using sys.settrace() so that every time the python interpreter does something it calls this method with the “event”.
On each call, the trace function is given the stack frame and a string with the name of the event type (e.g., call, line, return, exception).
The work for sending the event over the socket is in the send_notice() method, which does three things.
First, it figures out if the event should be recorded, based on the name of the file where it happened. Early versions ignored the standard library, though I later relaxed that and made it more flexible.
If a file should be included in the trace, then it builds a list of interesting local variables by looking at the stack frame.
A Python frame object includes every symbol, but smiley ignores any modules, functions, and methods because those aren’t as likely to change value over time as other types of variables.
Finally, it builds a standard data structure to hold the trace event data. At this point I was not worried about the database schema or anything like that, so the message is just a simple flat dictionary describing the event.
The next step was to build some sort of a UI for running programs and recording the trace.
A Command Line Interface
I started with some simple standalone scripts built on argparse, but as I thought about it I realized I would need several different commands for different tasks. As a developer tool, I wanted to make smiley easy to extend, and so I switched to cliff, a framework for building extensible command line tools.
Cliff relies on argparse for parsing options and setuptools entry points to discover available sub-commands defined as plugins. That means applications built on cliff can be extended by packages written by someone else, and that means that anyone can write their own extensions to smiley without them having to be built into the main application.
I needed a run command to set up the trace code and publish events to a ZeroMQ socket and a monitor command to listen for those messages and print them to the console.
Both commands default to a localhost socket, but it’s possible to specify another using a URL argument so remote monitoring is possible.
The monitor command sets up a listener to call its process_message() method to actually print the output. There’s a simple check to look at the event type, and then format the value accordingly.
Testing
To test all of this out I created a little script with a few functions that call each other with different arguments and return values. It is pretty simple but still includes some interesting cases like loops and generators.
In one terminal I can use “smiley run simple.py” to run the test script and then in another terminal “smiley monitor” collects the output. You can see that it isn’t terribly readable, but it was good enough to keep experimenting.
$ smiley monitor
Waiting for incoming data
MESSAGE: ['start_run', {u'command_line': [u'simple.py'], u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e'}]
Starting new run: [u'simple.py']
MESSAGE: ['call', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.142863,
u'line_no': 1,
u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py',
u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 1: import sys
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.143175,
u'line_no': 1,
u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py',
u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 1: import sys
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.143499, u'line_no': 3, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 3: def gen(m):
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.143815, u'line_no': 8, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 8: def c(input):
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.144169, u'line_no': 14, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 14: def b(arg):
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.144468, u'line_no': 21, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 21: def a():
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.144719, u'line_no': 26, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 26: a()
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['call', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.144927, u'line_no': 21, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'a', u'arg': None, u'locals': {}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 21: def a():
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.145128, u'line_no': 22, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'a', u'arg': None, u'locals': {}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 22: print 'args:', sys.argv
MESSAGE: ['line', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.145343, u'line_no': 23, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'a', u'arg': None, u'locals': {}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 23: b(2)
MESSAGE: ['exception', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.145528, u'line_no': 23, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'a', u'arg': [u"<type 'exceptions.NameError'>", u"global name 'b' is not defined", u'<traceback object at 0x103cb15a8>'], u'locals': {}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 23: b(2)
MESSAGE: ['return', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.145706, u'line_no': 23, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'a', u'arg': None, u'locals': {}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 23: return>>> None
MESSAGE: ['exception', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.145919, u'line_no': 26, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': [u"<type 'exceptions.NameError'>", u"global name 'b' is not defined", u'<traceback object at 0x103cb1878>'], u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 26: a()
command_line = [u'simple.py']
self = <smiley.tracer.Tracer object at 0x103caff10>
MESSAGE: ['return', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e', u'timestamp': 1436367235.14614, u'line_no': 26, u'filename': u'/Users/dhellmann/Devel/smiley/scratch/simple.py', u'func_name': u'<module>', u'arg': None, u'locals': {u'self': u'<smiley.tracer.Tracer object at 0x103caff10>', u'command_line': [u'simple.py']}}]
/Users/dhellmann/Devel/smiley/scratch/simple.py: 26: return>>> None
MESSAGE: ['end_run', {u'run_id': u'e87302b2-402a-4243-bb27-69a467d4bd8e'}]
Finished run
It includes the event types, file names, and line numbers. And, later in the output, when the program is inside a function, monitor shows the function name for each line as well.
At this point I had a run command to trace a user’s program and send the results to the monitor command, which would print everything out on the console. That’s a good early step, but not necessarily a “minimum viable product.”
The next step was to figure out where else to send the output.
Adding a Database
I decided I was going to want several commands for writing to different outputs so I needed to do some cleanup work and to refactor the existing monitor command to make a reusable base class.
I chose to work on recording runs for browsing and replay. I knew that to store the runs I wanted some sort of database.
As Python developers, we have a lot of database options.
I’ve used both ZODB and MongoDB before with good results, but neither quite had the query semantics that I wanted, in terms of being able to fetch a subset of the run easily.
After thinking about how I might implement replay, I knew I would want to select events in order, and very likely want to get information for just a subset of the events in a run. I also expected to need to find information like how long a run is in steps. I decided that those query patterns meant I should use a relational database.
I didn’t want to depend on having a separate server running, so I went with SQLite, since it is built into the standard library and available in most environments.
Smiley doesn’t use an ORM, but I did create a class to define the logical operations, such as start_run(). This lets me separate the data representation from the way I manipulate it.
I began with a single operation to start a run so I could prove to myself that a message coming from the run command process would make it through the ZeroMQ socket to the process recording the data then into the database where I could retrieve it later. That ensured I had all of the communication and transaction parts working, and then I expanded the API for more features.
The record command that writes to the database has a method for processing the messages that looks at the type to decide which DB API method to call, similar to how the monitor command checks the type before formatting the output.
To Use a Class, or Not?
This is the second place the pattern of looking at the event type and doing something different has shown up. Normally when you have a repeated pattern like that you look for a way to eliminate it and share code. In this case, I considered making each event type its own class to hide the behavior differences.
I realized that even if each message type was represented by a class, I would still need to do the work of turning a transmitted message into the right class anyway, and I wanted to keep the display and database logic isolated in their own classes, not scattered among the message type classes. So I chose to keep the basic data object as simple as possible and stick with checking the message type in a couple of places where the difference matters.
After I had enough of the pieces working to record the start of the run I could update both the record command and DB API to support ending a run and recording the intermediate trace items.
Iterating like this let me focus on one piece at a time:
- First set up ZeroMQ communication,
- then hook into the trace to observe the program,
- then send that data to the console to check it visually,
- then build up the database handling piece by piece.
Each step along the way I only needed to learn one tool at a time or think about one API at a time. Now that I had a basic way to record program runs, I had to decide what to tackle next.
Complexity
I could start building the database query API to let me replay old runs, or I could look at some of the more complex data types.
I knew that if I started working on the replay feature, I might have to rewrite part of it after implementing the complex data type support, so I decided to start with extending the capture to support those complex types.
I had reserved a column for recording the final exception from a program that dies with an error, but at this point I was only recording the error message and not the full traceback. That made a good starting point, since I needed to do more to produce a useful representation of the traceback, so I wrote some custom JSON encoding logic to handle complex types.
The traceback module has an extract_tb() function tailor-made for getting the traceback data into a structure that is easier to format, so I started with that and then added more general support for instances of other complex types using a dictionary containing the class name, the module where the class can be found (in case the name is not unique) and then the attributes of the object.
All of those lower level types can be serialized directly, so after implementing the conversion I could send and store complex data but I still had no way to replay old runs from the database.
I knew I had the formatting code I needed in the monitor command, so I started by refactoring that implementation out into its own module so I could reuse it from the new command I was planning.
And that’s where I had a sort of epiphany.
Design Breakthrough
It seems like a small thing in retrospect, but at the time it made a big difference to realize that the output formatter, database API, and the ZMQ publisher all shared a common pattern, they all need to perform the same 3 operations.
I realized with a little work they could all share a common API, so I defined a new EventProcessor base class and fixed up the APIs for the existing classes to match it, including renaming some methods and arguments.
class EventProcessor(object):
__metaclass__ = abc.ABCMeta
@abc.abstractmethod
def start_run(self, run_id, cwd, description,
start_time):
"""Called when a 'start_run' event is seen.
"""
@abc.abstractmethod
def end_run(self, run_id, end_time, message,
traceback):
"""Called when an 'end_run' event is seen.
"""
@abc.abstractmethod
def trace(self, run_id, event,
func_name, line_no, filename,
trace_arg, local_vars,
timestamp):
"""Called when any other event type is seen.
"""
Then I went on to work on the replay command, except I realized there was no way for me to test that command until I had a way to get a list of the runs from the database. Up until this point I had been looking at the database directly or reading monitor output, so I hadn’t needed a list command. So, first a list command, then the replay command which, with the new EventProcessor API turned out to be fairly straightforward. I added new methods to the DB API to return the run record and related trace records, and then loop over the results calling the appropriate methods on the output formatter.
Incomplete Data
Around this time I discovered an issue with storing the program trace data.
One of the features of both the monitor and replay commands is showing the line of source code being executed with the variables as context.
This was implemented originally using the linecache module from the standard library, which has an API for finding line N of a given file by name.
However, as I continued to run tests and experiment, I realized that replaying a very old run was showing the wrong source lines because I was changing the input program. The feature also wouldn’t work properly for remote monitoring, since the source files might not be on the record and replay machine at all. I was going to need to save the source code of the program as it ran, too, in order for the history to be accurate.
So, I added some calls to the database API to let me store the source code there in a new table and updated the run command to send a copy of each new source file it encountered across the socket to the record command. Then I created a DBLineCache class with the same getline() API as the linecache module, but that reads the files out of the database instead of from the filesystem. It’s not a complicated class, but it let me substitute an instance of the new class where I was using linecache before, and not change the output formatter implementation.
Improving the UI
At this point, I was running record and run commands over and over, and getting a little tired of using them as two commands. I wanted to keep record for remote debugging, but I knew smiley would be more usable if I could just use the run command when working locally. To do that, I needed to teach it how to write to a database instead of a socket.
Since my DB API was in part derived from the EventProcessor base class, I knew I could just instantiate a DB and pass it to the tracer. I added a command line flag to run to switch between a remote connection and a local database and dropped the database instance in instead of the network publisher.
That’s two cases where by identifying an abstract API, I could provide separate concrete implementations and improve flexibility and reuse.
Iterative Development Pattern
Now I had something that was usable for very simple python programs and the iterative pattern in my development process should be clear.
I learned to use a new tool, used it to build a feature, evolved the feature by enhancing it and fixing bugs, and then started on the next feature.
So far we’ve seen nine of these iterations, starting with the basics of ZMQ and SQLite and moving on to various smaller usability enhancements.
- ZMQ
- Tracing
- Command line interface
- Database
- Complex objects
- EventProcessor API
- Replay command
- Store source files
- Local database
Moving to the Web
As I worked, I built up quite a database of test runs, and I wanted a better UI for browsing them instead of typing lots of job ID values on the command line. I transitioned into the next major feature addition cycle by starting the web interface or “server” mode.
As with the command line tools I didn’t want to build everything from scratch, and this was definitely an area where I needed to go outside of the standard library. I’m no web designer, so I knew I was going to need a framework to do most of the heavy lifting. I started out with PureCSS, which I had used for my blog, but ended up switching to Bootstrap because it has better widget support.
I chose Pecan as a web framework, since I had used it recently for some other work and I know the maintainers through the Atlanta meetup. Pecan uses Mako templates by default, and I hadn’t really used those much, so between figuring out Mako and Bootstrap it took me a while to put together a basic page.
As with replay I had to start with showing a list of the existing runs.
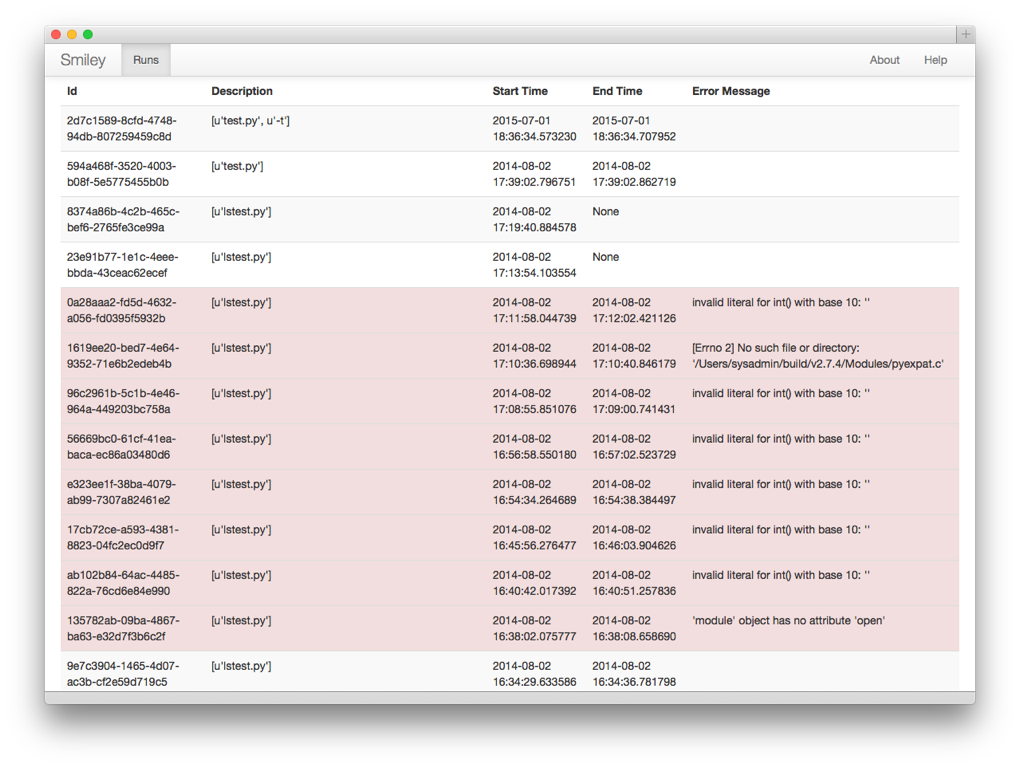
The table showing run IDs, times, and outcome, is a little easier to read here than the list command output was on the console.
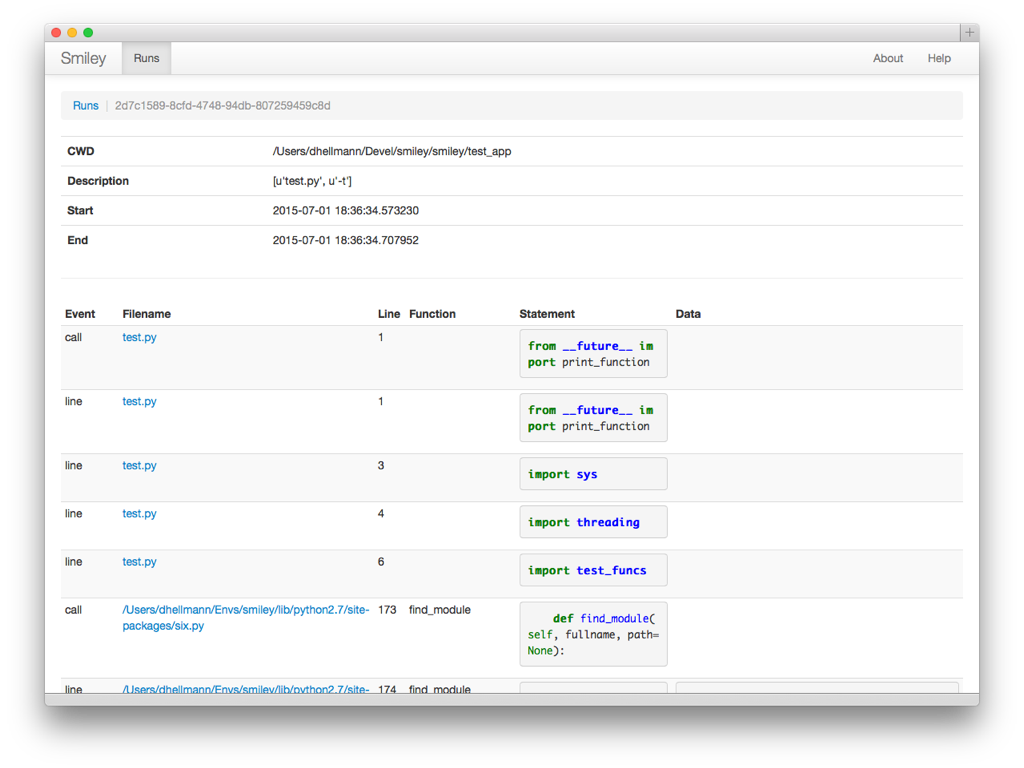
Next I turned those run values in the left column into links and wrote a view for the trace data.
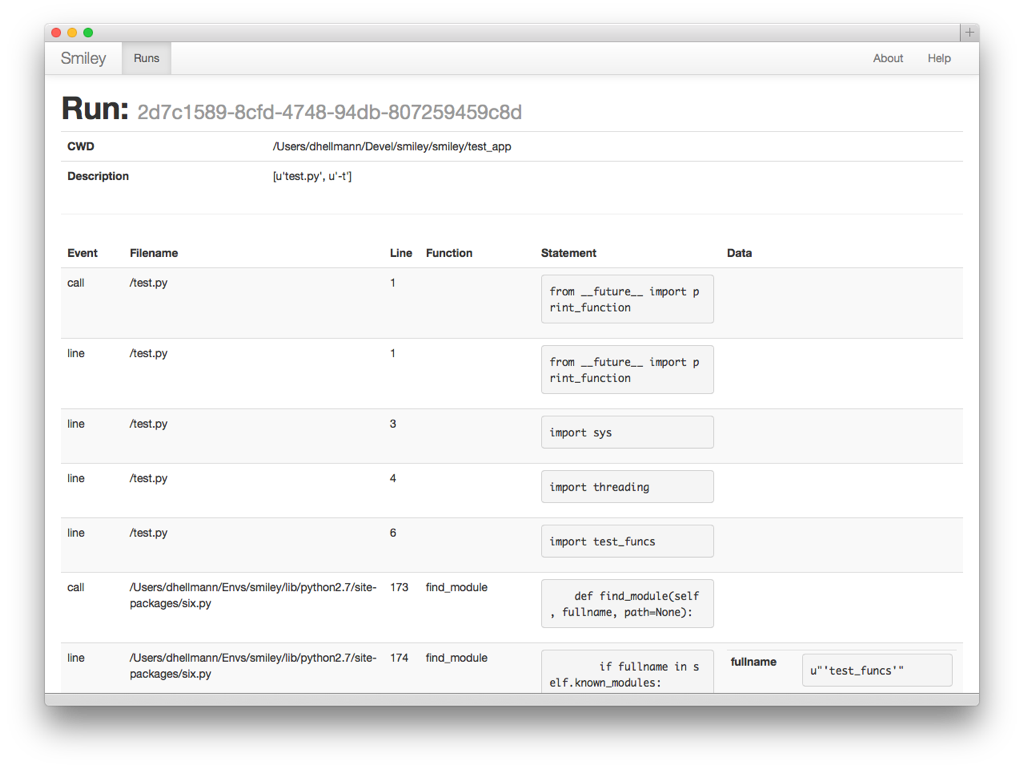
The trace shows each line of the script being run, just like the console app.
For the web app I wanted to be able to show the complete contents of source files, too, so I needed a new view that could pull the file contents from the database and show them. Of course, plain text in a browser window is boring so I hooked up the PYGMENTS library so I could have syntax highlighting.
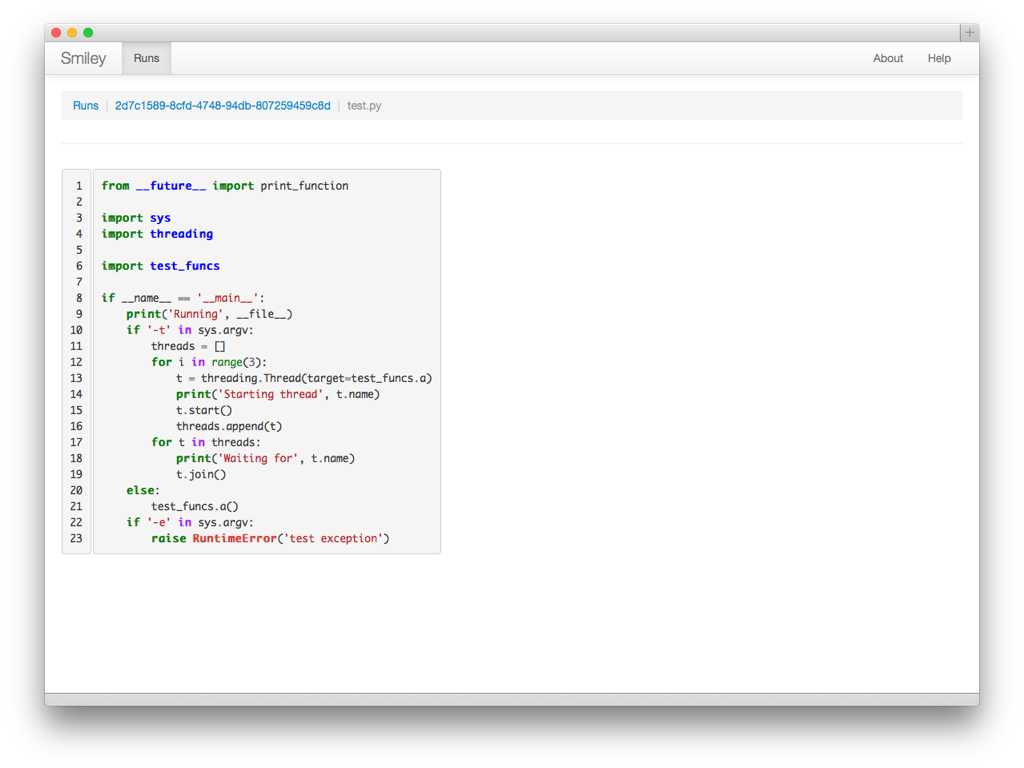
That involved reading the body of the file from the database, and passing it to pygments to render as HTML, and adding the appropriate CSS block to the stylesheet for the app. The results are a nice improvement over the plain text.
It was a little more challenging to add syntax highlighting to the trace view, which is showing one line at a time. Pygments doesn’t always know how to parse a partial statement or snippet of source code so I wanted to feed the whole file to it to ensure the parser would understand it.
Studying the pygments output, I noticed that it preserved the original line formatting, with a little bit of prefix and suffix text for the whole block of output.
Using that information, I went back and created another line cache implementation. This one takes the full pygments output for a file, trims the header and footer, saves the part that represented the actual source code, and return lines from that instead of the raw plain text in the database.
Again, I was able to drop this class in to replace the old version, and then the web UI had syntax highlighting in the trace output, seen here in the statement column.
Adding syntax highlighting to the local variable definitions and return values in the far right column was a little simpler because those were fully valid expressions.
Profiling
Now I could see what my program was doing, and easily browse through the trace output. The next thing to do was make it easier to understand where it was spending lots of time.
I had originally thought I would keep up with this sort of data myself using unique IDs for each call and using the time values to build the necessary statistics — basically building my own profiler.
Then I looked again at Python’s profiler and trace APIs, and realized they used different hooks, so they could both be used together. Instead of building my own profiler, I just turned on the built-in profiler and collected the data, sending it across the socket at the end of a run.
I added a new web view to show the profile stats data as a table.
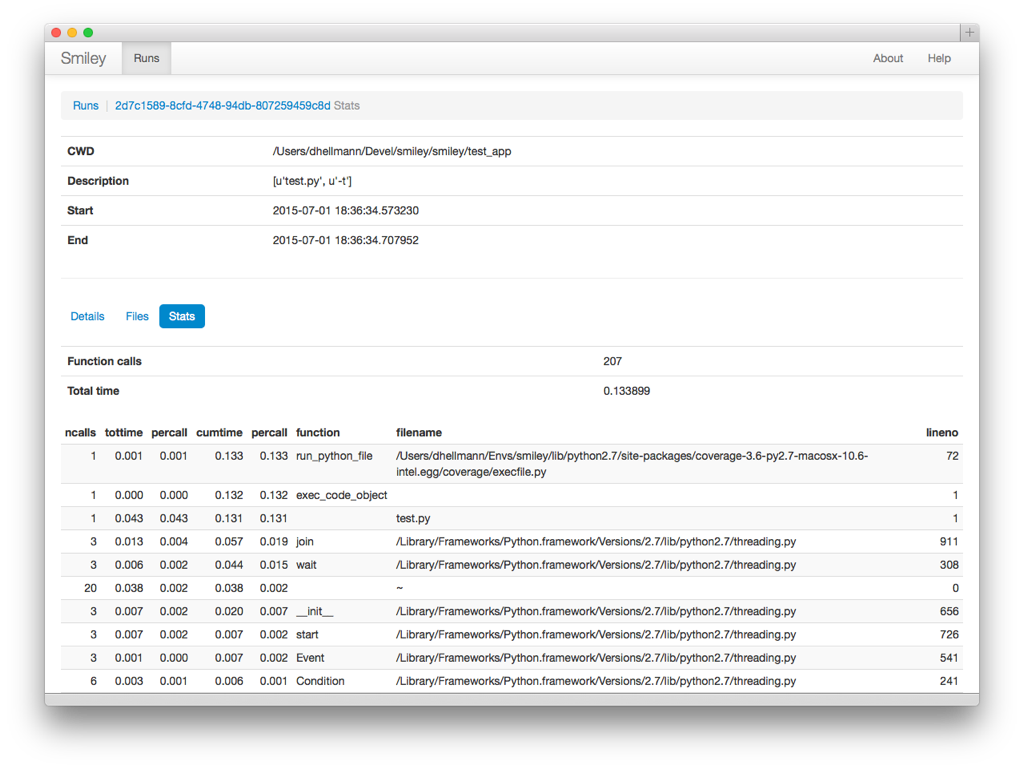
Then Ryan Petrello showed me how to generate a visualization.
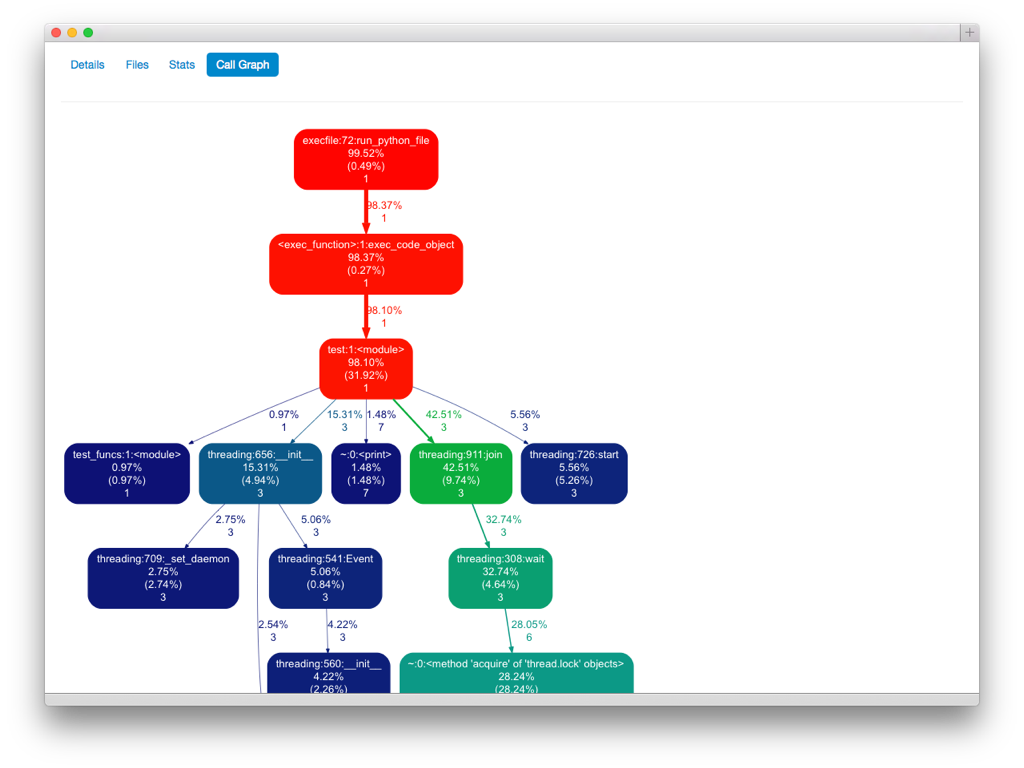
I added another view that shows that diagram with colors to indicate where in the call tree the program spends most of its time.
Highlighting Changes in the Output
After adding the profiler support, I had reached another plateau in my feature work and was ready to move to the next step in that learn, build, evolve cycle.
I noticed that the web UI was showing a lot of the same data over and over, so I decided to make it only show local variables as their values changed from line to line. I also thought about how important comments are in understanding a program, so I decided to try to show comments near code that had been executed.
I started with detecting changes in variables.
The first version of this used difflib on a sequence of sorted variable names and their representations. This was pretty convenient, since difflib works on any two sequences and would tell me what had been added or changed (to be displayed). That let me remove this duplicated data, by comparing the local variables at each line with the ones from the previous line.
Any time execution enters or leaves a function, it automatically triggers re-dumping the local values for the new context. Within a given function scope, only the variables that actually changed are shown.
The result was output with lots of lines without any variables, because they didn’t change very much. That gave me the idea to collapse those rows together and show them as a block of source instead of one line at a time.
I wrapped the existing iterator of trace data in another generator function that produced the aggregate values as a series of ranges. Rather than have the template make a bunch of calls to get each line separately, I extended my already customized line cache class with a getlines() method that retrieves multiple lines with one call.
Next, I extended getlines() to include comment lines immediately preceding the start of the requested range.
At this point I was doing quite a bit of processing of the data in the UI, and it was starting to seem slow. I knew that the problem would only become worse as the length of program runs grew so,
Adding Advanced Features
I decided to add pagination to the UI to address that. After pagination was working, I added a few other features.
Multi-threaded programs record the thread id of each step of the program, and the UI lets you filter the output by thread.
There is a command for generating a static HTML report, which can then be published on a website and shared.
And there are also commands for exporting raw run data from one database and importing it into another.
Each of these feature development cycles followed the same learn, build, evolve process.
Time Investment
When I told this story to my meetup group, I called smiley a “weekend project”. Someone in the group misunderstood that to mean I had written the project over the course of weekend, maybe because that presentation was relatively short like this one. In fact, it took me a couple of years of work, in my spare time.
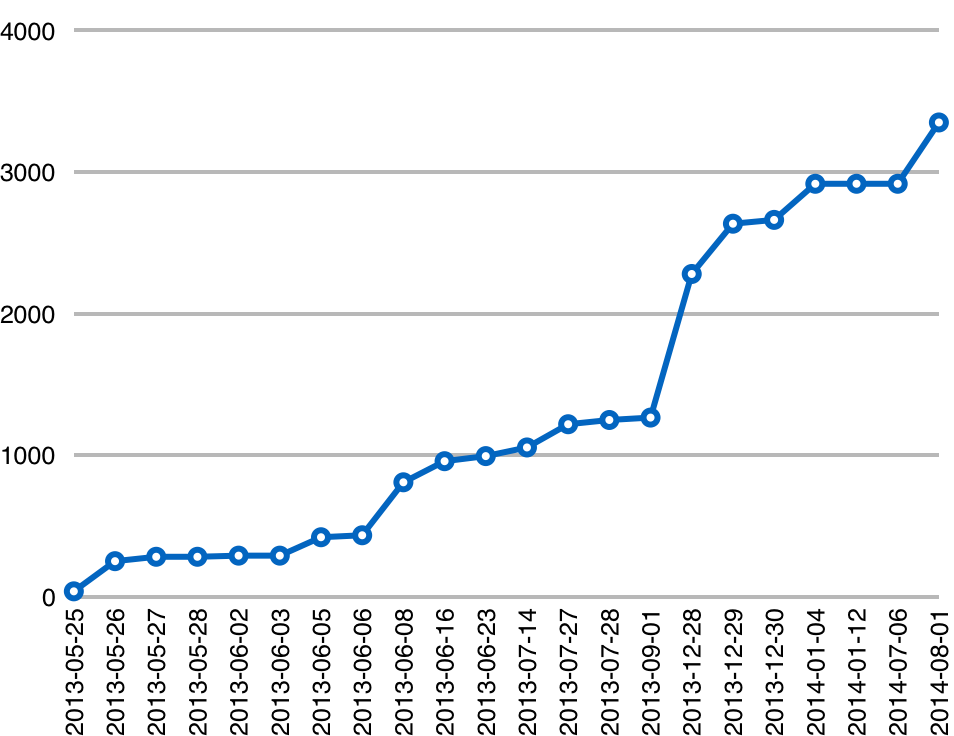
This chart shows the days on which I had commits, and the lines of code at the end of each day. There were almost always more than one commit on any given day, but I collapsed those to make the graph easier to follow.
If we accept lines of code as a rough analog for project feature and complexity growth, you can see a relatively steady progression resulting from that iterative process. The one notable exception is that big jump around the end of 2013, which is when I committed a large batch of CSS and template code for the static report generator. But you can see that slowly, over time, smiley grew from a very rudimentary trace monitoring tool, to have a full browser-based GUI and some fairly advanced collaboration features.
If I had been working on smiley full time rather than my spare time, I think it still would have taken a couple of months worth of effort.
The graph doesn’t show the time I spent researching and experimenting with new tools, or thinking about features and making the decisions I’ve described today, or backing up and starting over when I ran into problems like choosing the wrong ZMQ socket type. So while I’ve compressed the story into about 20 minutes, it really took far longer.
The Future
There are still a lot of things I would like to add to make smiley even more useful.
Capture performance work is probably the biggest need.
Pre-calculating and storing the collapsed trace views would also be an improvement.
There are several smaller UI enhancements on the list, too.
But beside the possibility of enticing some of you to contribute I hope after hearing the history of Smiley, you’re inspired to write or talk about your own projects in a similar way.
Whether that’s on your blog, at a meet-up, or a conference, it’s important to talk about design decisions, mistakes, and iterative development — to talk about learning how we learn — as we help each other grow.
To that end, I hope you will share your experience, not just your results.